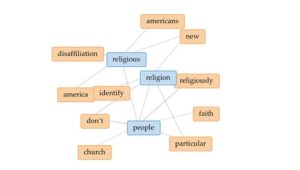
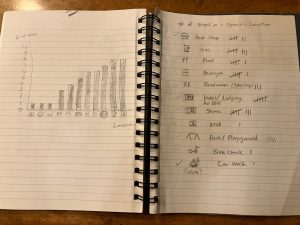
When I first started this course, I truly didn’t know what to expect. I couldn’t really give a solid definition of digital humanities. I understood that this course would likely use digital tools to explore the field of religious studies. The first class text we worked with, Observe, Collect, Draw!, made me question my original thoughts on the digital part of the course. However, after our first few labs and exercises focusing on collecting data in creative and unique ways, I began to understand the importance of understanding data in any research as well as analyzing data in the traditional sense. It also became clear as we explored digital humanities through various projects, encoding, working with visualizations, and content management systems that data could be easily manipulated and was subjective and open to interpretation. Specifically, I learned that while data is important to studying the humanities and in religious studies, it also has its limitations and needs to be approached objectively and with accessibility and sensitivity of different culture groups in mind. Finally, it was only after I began work on my final essay that it all came together for me in connecting all of the digital skills I learned with research in religious studies.
So now digital humanities for me can be defined as the use of technology to theorize, research, report, and share information on different historical, cultural, religious, and social questions. Digital humanities in religious studies can be used to research how data was historically collected, how data is currently used, and challenge any personal bias of researchers when answering questions related to religious studies research. The technology I learned in this course will be extremely helpful in how I interpret not only academic research, but any digital information and visualizations I encounter on a daily basis.